
티스토리 뷰
레거시 시스템을 살펴보면 도메인에도 @Data, @Setter가 달려있는 모습을 볼 수 있다
불변의 중요성이 커지면서 & 무분별한 setter로 인해 변경점 파악이 어려워 @Setter는 안티 패턴과 같이 여겨지고 있다
@Setter와 같은 역할을 하더라도 더 의미 있는 changeXX() 등의 네이밍이 권장되고 있다
그렇다면 레거시 시스템에서는 @Setter를 왜 썼을까?, 개인적인 생각에 다음과 같은 이유지 않았을까 싶다
1. setter와 이름만 다르지 역할은 같은 수 많은 메서드를 만들기 귀찮음
2. @RequestBody, @ModelAttribute 바인딩을 가장 쉽게 할 수 있는 방법이므로
언젠가 코드리뷰에서 DTO에서 매핑이 안 되던 문제가 나왔던 적이 있다
입사한 지 얼마 안 된 신입 시절에 왜 매핑이 안 되는지 나한테 질문이 왔었는데
그때는 무엇이 잘못된 건지 몰라 제대로 대답을 하지 못 했던 기억이 있다
답은 간단하게도 @Setter가 달려있지 않아 매핑이 안 되던 것이었다, 리뷰 때 나왔던 DTO의 형태는 아래와 같았다
@NoArgsConstructor
@Getter
public class DTO {
// blahblah..
}
@Setter를 달아야 한다는 피드백을 받고 마음 한편에 찜찜함이 남아 왜 @Setter가 없으면 안 되는지
궁금함을 참을 수 없어 @RequestBody, @ModelAttribute의 매핑 방식에 대해 찾아봤다
결론으로 다음과 같은 형태로 도메인이나 DTO 작성 시 @Setter 없이 매핑이 문제없이 수행됨을 알 수 있었다
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
public class DTO {
// blahblah..
}
그 이유를 알고 싶다면 테스트에 필요한 도메인과 컨트롤러를 참고하여
자신의 프로젝트에 복붙 후 디버깅을 따라가보도록 하자
다만 친절한 설명을 하기에 내용이 너무 방대해 어떤 흐름으로 찾아가면 되는지만 보려 한다
사진과 짧막한 설명만 넣었음에도 불구하고 내용이 많아서 궁금한 분들에게 도움이 될 수 있을까 의문이 들긴 한다
분량 상 이번은 @RequestBody 처리만 다루고 다음 글에서 @ModelAttribute에 대해 다뤄보려 한다
@XmlAccessorType(XmlAccessType.PROPERTY)
@XmlRootElement(name = "data")
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
@ToString
public class TestRequest {
@XmlElement(name = "xml_name")
private String name;
@XmlElement(name = "xml_age")
private int age;
@XmlElement(name = "xml_inner")
private TestInnerRequest testInnerRequest = new TestInnerRequest();
@XmlAccessorType(XmlAccessType.PROPERTY)
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
@ToString
public static class TestInnerRequest {
@XmlElement(name = "xml_inner_name")
private String innerName;
}
}
@Slf4j
@Controller
public class MappingTestController {
@ResponseBody
@PostMapping(
value = "/test/request-body",
produces = { MediaType.APPLICATION_JSON_VALUE, MediaType.APPLICATION_XML_VALUE }
)
public TestRequest testRequestBody(@RequestBody TestRequest testRequest) {
log.info("testRequest = {}", testRequest);
return testRequest;
}
@ResponseBody
@PostMapping(
value = "/test/model-attribute",
produces = { MediaType.APPLICATION_JSON_VALUE, MediaType.APPLICATION_XML_VALUE }
)
public TestRequest testModelAttribute(@ModelAttribute TestRequest testRequest) {
log.info("testRequest = {}", testRequest);
return testRequest;
}
}
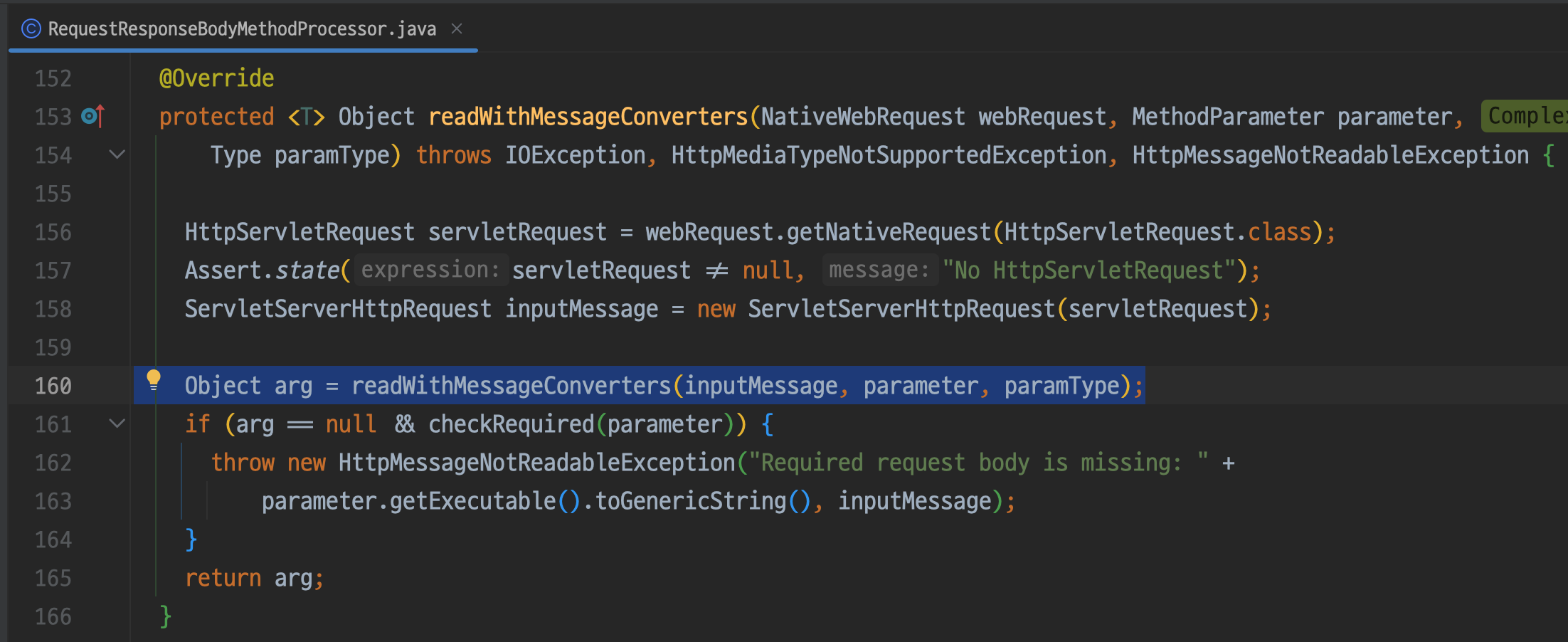
참고로 지금부터 알아볼 방식은 어떻게 해서 인자들이 매핑되는지에 대해서다
어떤 녀석이 인자 매핑을 시작하는지 궁금하다면 역순으로 readWithMessageConverters를 호출하는 쪽을 찾아보면 된다
HttpMessageConverter로 요청과 응답 본문을 읽거나 쓸 때
@RequestBody, @ResponseBody 애노테이션이 붙어있는 경우 인자를 매핑해주는 녀석이라 한다

어떤 검증 과정이 있는지 자세히 설명하려면 한 세월이고 나도 다 파악하지 못했으므로 담백하게 가장 빠른 길로 찾아가 보자
아래와 같이 드래그한 부분을 이어서 찾아가 보면 된다
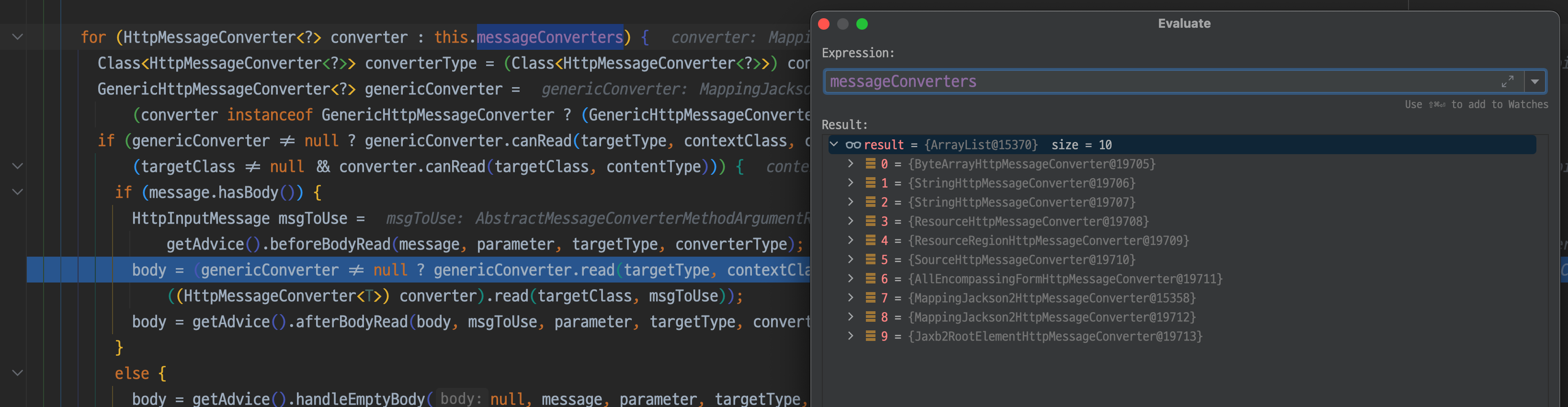
GenericConverter로 등록되어 있는 AbstractJackson2HttpMessageConverter가 호출된다

기본적으로 messageConverters에 10개의 범용 Converter들은 이미 등록이 되어있다
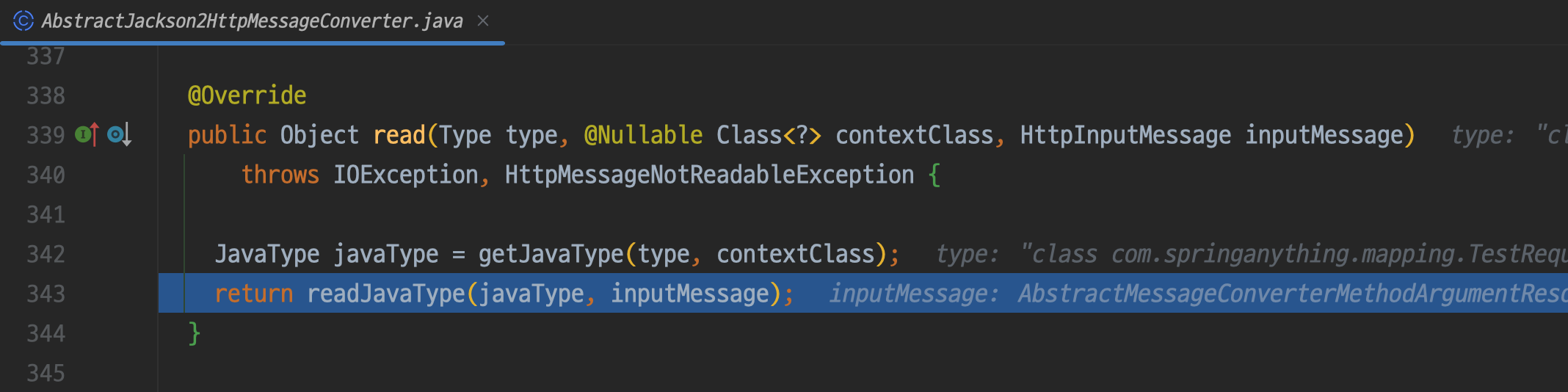
input으로 들어온 값의 type을 추론해 얻은 javaType과 input 자체를 넘겨 객체로 변환을 수행한다
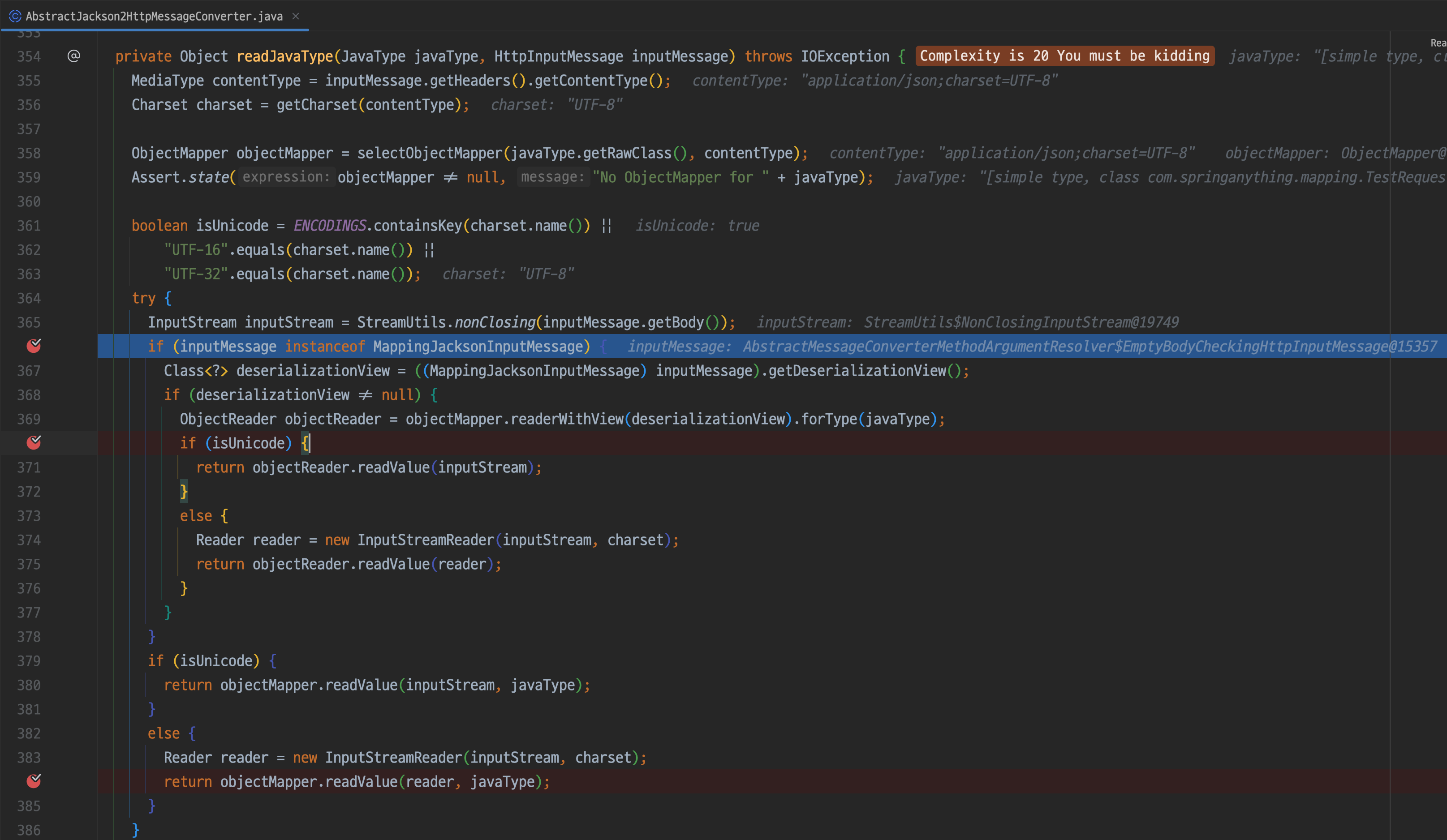
inputMessage의 타입을 체크한다, MappingJacksonInputMessage인지를 확인하는데
여기서 inputMessage를 evaluation 해보면 EmptyBodyCheckingHttpInputMessage가 나와
결과적으로 380라인의 objectMapper.readValue(inputStream, javaType)을 타게 된다
EmptyBodyCheckingHttpInputMessage가 무엇인고 하니 등록된 messageConverters들로 순회하면서 읽기 바로 전
inputMessage를 인자로 생성하는데 메세지 본문이 비어있는지 확인하기 위해 사용하는 Wrapper라 생각하면 된다

이어서 ObjectMapper의 메서드로 들어가 보면 자신의 메서드를 호출하고 있다

JSON이 '{' 문자로 시작하는지 확인하는 과정을 거쳐 값을 읽는다
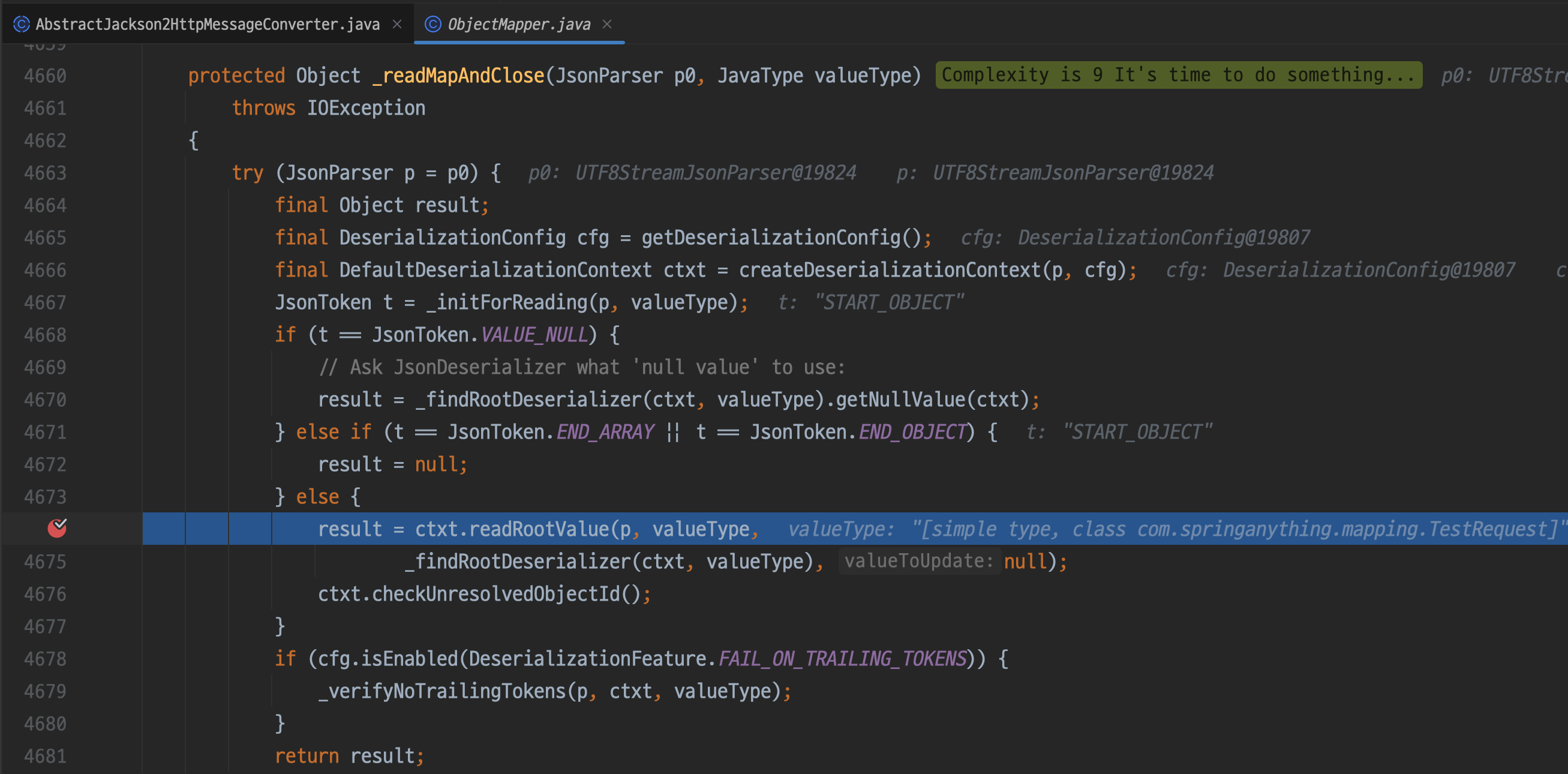
매핑하고자 하는 값이 String, Integer 같은 기본 타입이 아니라 객체 타입이므로
이전에 호출되었던 _findRootDeserializer(ctxt, valueType)에서 BeanDeserializer가 반환된 모습이다

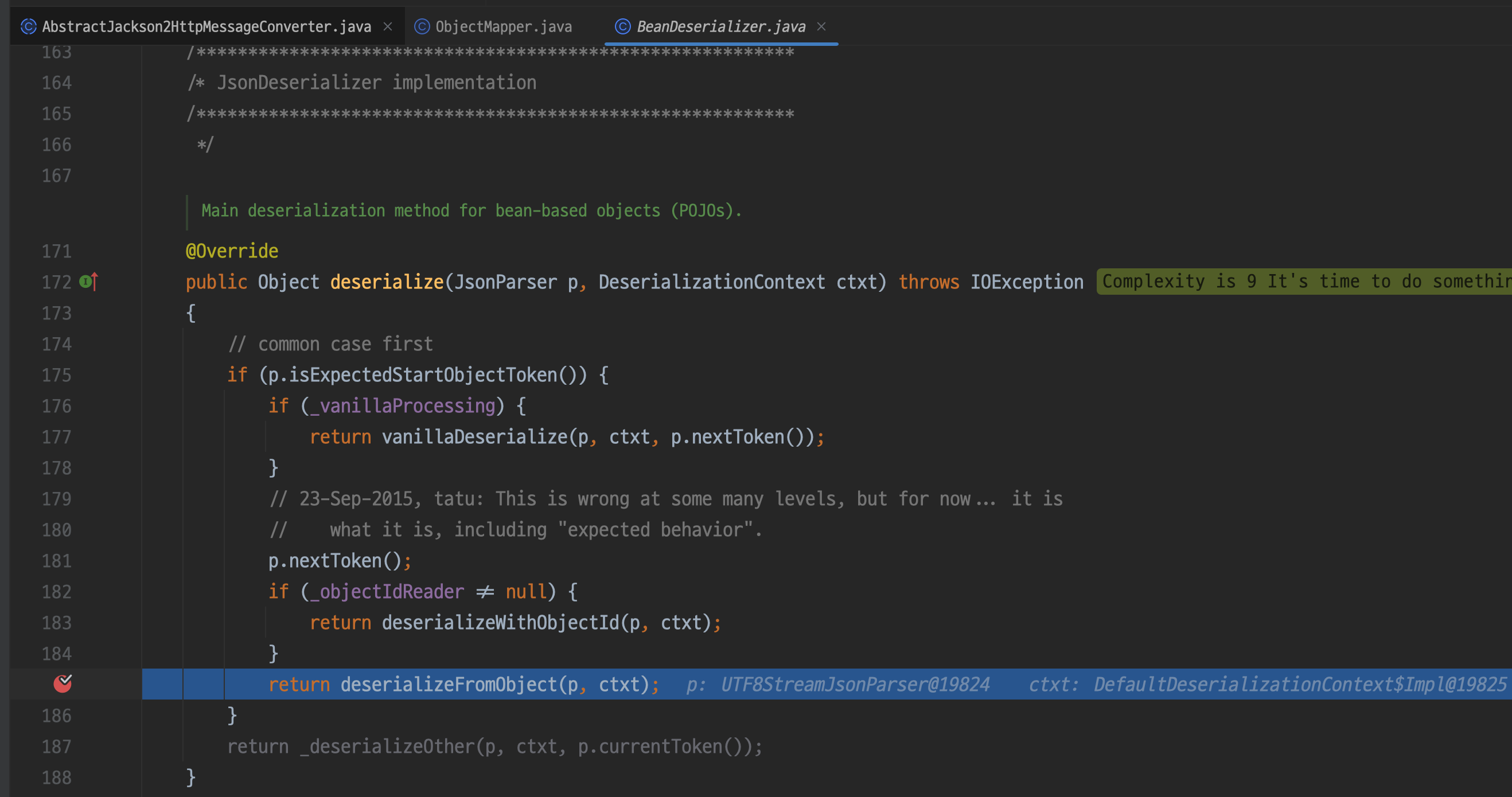
어떤 방식으로 생성됐는지 체크하고 기본 생성자를 이용해 생성했다면 디버그를 찍어둔 367라인으로 넘어간다

기본 생성자 (인자가 하나도 없는 생성자, 즉 @NoArgsConstructor)를 사용하지 않고
특수한 방식으로 생성하는 경우 _nonStandardCreation가 true가 세팅된다
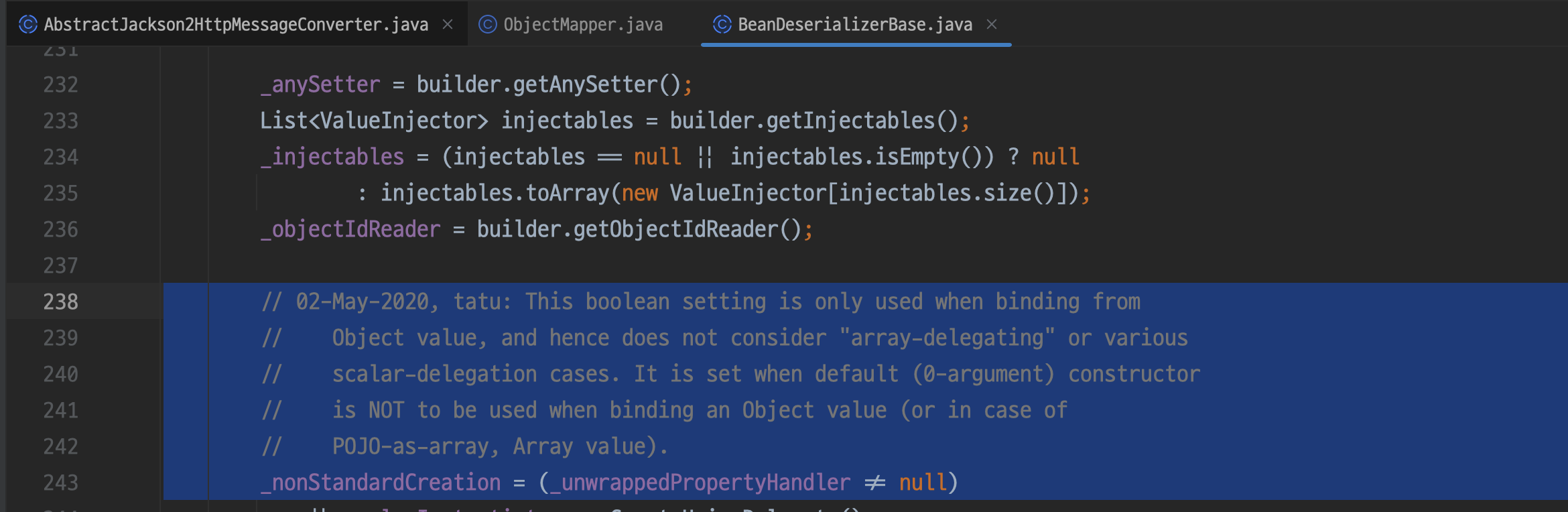
BeanDeserializerBase는 BeanDeserializer의 뼈대 클래스라 생각하면 된다
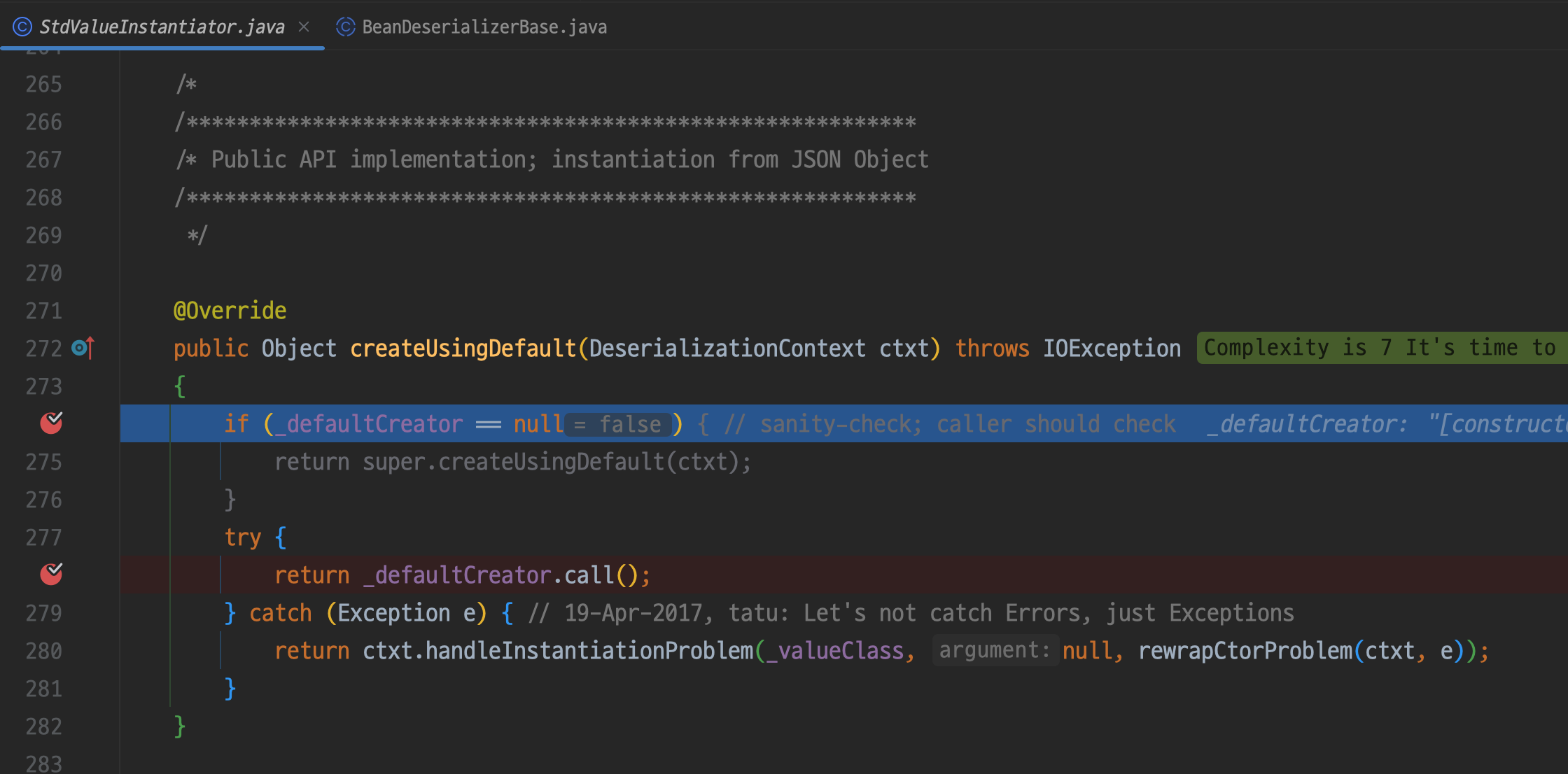
메서드 이름 그대로 default 생성자가 있는지 확인하여 없다면 super.createUsingDefault(ctxt)를 이용해
기본 구현되어 있는 그대로 예외를 터트리고 있다면 생성자를 호출해 초기화된 객체를 반환한다
JSON 매핑 시에 기본 생성자를 생성해두지 않으면 예외가 터지는데 그 원인이 이곳이다
이후 deserializeFromObject 메서드로 돌아와 객체에서 필드 수만큼 반복문을 돌며
392 line, prop.deserializeAndSet을 따라가 값을 세팅해준다

이때 내부적으로 Reflection API를 사용해 fieldOffset과 type 등을 체크하여 값을 넣어준다
여기까지 어떤 방식으로 값이 주입되는지 확인했는데 그렇다면 서두에 설명한
@NoArgsConstructor는 이해가 될텐데 @Getter의 필요성은 이해 가지 않을 것이다
간단하게 말해 ObjectMapper가 필드명을 알아내기 위해 setter 혹은 getter를 이용하기 때문이다
예를 들어 setField1 -> field1, getField2 -> field2 같은 형태로 동작한다
setter나 getter 둘 중 하나는 반드시 있어야 하며 없는 경우 필드명을 알아낼 수 없어 매핑되지 않는다
자세한 설명은 다음 글을 참고하자 - https://jenkov.com/tutorials/java-json/jackson-objectmapper.html
아래 예를 참고해 lombok.config 파일에 lombok.setter.flagUsage = error 옵션을 주면
프로젝트 전체에서 @Setter 사용 제한을 둘 수 있다, lombok.config 파일은 프로젝트 루트에 두면 된다
GitHub - tokuhirom/java-samples
Contribute to tokuhirom/java-samples development by creating an account on GitHub.
github.com
'Spring > Spring MVC' 카테고리의 다른 글
| multipart/form-data 요청과 non-ascii filename (0) | 2023.09.29 |
|---|---|
| CommonsMultipartResolver vs StandardServletMultipartResolver (0) | 2023.04.09 |
| @RequestBody, @ModelAttribute 매핑 방식의 이해 - 2 (0) | 2022.12.25 |
| [Swagger2] Failed to start bean 'documentationPluginsBootstrapper'; (0) | 2022.03.27 |